Unicity Distance
Introduction §
The Unicity Distance is a property of a certain cipher algorithm. It answers the question 'if we performed a brute force attack, how much ciphertext would we need to be sure our solution was the true solution?'. The answer depends on the redundancy of English. A short example should hopefully illuminate the problem:
Say for example we are given a message to decipher: FJKFPO, and we know it is enciphered with a substitution cipher. Can we decipher it? The answer is 'not really'. We can find many english words that fit the pattern, sure, but we can never know which was the actual original plaintext. For example, all of the following english fragments are legitimate decryptions for the ciphertext above, and we have no idea which is correct:
thatis ofyour season onyour thatwe thetop thetwo oxford thatin thatof
and many more. The longer the ciphertext, the fewer possible decryptions there are. We wish to know, how long does a piece of ciphertext need to be, before it has only one possible decryption? This minimum length is given by the unicity distance.
Redundancy §
The substitution cipher has a key that consists of 26 letters. The total number of keys is the number of ways we can jumble 26 letters, or 26! (factorial), this is very large number of possible keys. The amount of information this carries, measured in bits, is given by the logarithm to base 2:
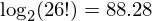
or around 88 bits. The amount of information (per letter) carried by an alphabet of 26 letters is 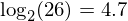 bits. The actual amount of information carried by english has been reported to be around 1.5 bits per character. This means the redundancy of english is around 4.7 - 1.5 = 3.2 bits per character.
bits. The actual amount of information carried by english has been reported to be around 1.5 bits per character. This means the redundancy of english is around 4.7 - 1.5 = 3.2 bits per character.
Unicity Distance §
The unicity distance is the ratio of the number of bits required to express the key divided by the redundancy of english in bits per character. In the case of the substitution cipher above, this is 88.28/3.2 = 27.6. This means 28 characters are required, minimum, to be sure a particular decryption is unique. Different ciphers have different unicity distances, a higher unicity distance generally indicates a more secure cipher.
The unicity distance calculation is based on all keys being equally probably. If the key for a cipher is an english word, this limits greatly the number of possible keys. As a result the Unicity distance will be lower. The unicity distance calculated for several common ciphers is shown below:
| Cipher | No. of keys | Unicity dist. | Details |
|---|---|---|---|
| Atbash cipher | 1 | 0 characters | |
| Caesar cipher | 25 | 2 characters | |
| Affine cipher | 311 | 3 characters | |
| Simple Substitution cipher | 26! | 28 characters | |
| Homophonic Substitution cipher | N!/(N-26)!*26^(N-26) | 1.47N - 49.91 + 0.45(0.5+N)Log[N] - 0.45(N-25.5)Log[N-26] | approximate. N is the number of cipher letters. N must be greater than 26. Unicity for N=30 is 38.1 characters |
| Vigenere cipher | 26^N | N*1.47 characters | N is the key length, e.g. N=10 means 15 characters are required. |
| Autokey cipher | 26^N | N*1.47 characters | Same as Vigenere. |
| Porta cipher | 13^N | N*1.156 characters | N is the key length, e.g. N=10 means 12 characters are required. |
| Playfair cipher | 25! | 27 characters | |
| Foursquare cipher | (25!)^2 | 53 characters |
Note that just because you have 30 characters of ciphertext for a substitution cipher, this does not mean you will be able to break it. The Unicity distance is a theoretical minimum. In general you may need 4 times more characters (100 or more) to reliably break substitution ciphers. The same problem exists with the other ciphers.
One Time Pads §
It was noted by the discoverer of the unicity distance that in a system with an infinite length random key, the unicity distance is infinite, and that for any alphabetic substitution cipher with a random key of length greater than or equal to the length of the message, plaintext cannot be derived from ciphertext alone. This type of cipher is called a one-time-pad
, because of the use of pads of paper to implement it in WW2 and before.
The Vigenere cipher with a key chosen to be the same length as the plaintext is an example of a one-time pad (only if the key is chosen completely randomly!). For any ciphertext we get, every single decryption is just as valid as any other.
comments powered by Disqus